在数字货币领域,以太坊 1.0 所采用的 PoW 算法具有神秘性与独特性。它与其他算法相结合后产生的变种,存在许多值得深入探究的方面,无论是其与内存之间的特殊关系,还是其对抗 ASIC 的相关策略等。
PoW算法与内存关联
传统的 PoW 算法不太注重内存这一因素。以太坊 1.0 中的 PoW 算法,其计算效率与 CPU 基本无关,而是与内存大小和带宽有关。比如一些常规大规模部署的矿机芯片,本想通过共享内存来提升挖矿效率,但却无法获得线性或超线性增长,这就是它区别于传统算法的特别之处。实际情况是,全客户端和矿工需要存储 1GB(初始大小)的 DAG 数据集,并且在挖矿时还得根据需要从其中获取数据。
这种内存关联在轻客户端上有所体现。轻客户端只需存储 cache 便可进行高效校验。在实际操作场景中,仅凭借 cache 中的少量数据,就能算出 DAG 指定位置的数据,从而保证了轻客户端即便不存储完整的 DAG,也依然能够在挖矿工作中起到应有的校验作用。
对比传统算力敏感型算法
比特币将 hash 算法应用于 PoW,许多数字货币也照抄了这一设计。拿 MD5 作为例子,这类已经被弃用的算法,在设计之初是对算力敏感的。在数字货币发展的早期,算法更倾向于一种思维模式,即把计算资源当作瓶颈,比如主频越高的 CPU,其进行 Hash 的速度就越快。
以太坊 1.0 的 PoW 算法是另寻途径。过去算力敏感算法处于主流地位,之后人们察觉到这种情况会过度依赖计算能力,为了摆脱这种不利局面,便开始关注存储依赖,也就是内存依赖,这是以太坊 PoW 算法产生的一个重要原因背景。
IO饱和策略对抗ASIC
ASIC 在数字货币挖矿领域一直存在争议。以太坊 1.0 的 PoW 算法运用了 IO 饱和策略以对抗它。此策略使得内存读取成为采矿的限制因素。如此一来,那些计算能力极为强大的 ASIC 设备便无法施展其在算力方面的巨大优势。
以实际的挖矿情况为例,若一个挖矿团队在挖矿时过度将精力投入于提升运算速度,却忽视了对内存读写速度的优化,那么在以太坊挖矿中,他们是无法获取到优势的。只有平衡好运算和内存读写的能力,才能够提高挖矿效率。而这一策略在很大程度上对挖矿生态的公平性起到了保障作用。
DAG的两个重要特点

DAG 在该算法中极为重要。它具备了内存难解以及内存易验证这两种特点。计算每一个 nonce 仅仅需要 DAG 的一小部分,然而采矿过程必须存储完整的 DAG。在通常的时间内,不能每次都计算 DAG 的子集,不过验证过程是可以计算子集的。
从实际的运行情况来看,如果 DAG 数据出现问题,像部分数据丢失或者出错这类情况,那么整个挖矿或者验证的工作就会遇到阻碍。算法通过保证对 DAG 的正常访问和使用,以此来确保系统能够稳定运行。

DAG的生成与等待时间

DAG 的生成需要耗费较多时间。其生成仅取决于区块数量,在每个 epoch 过渡之际,倘若按照需求去生成 DAG,那么在新的 epoch 第一个区块产生之前,就需要等待很长时间。接着,我们能够预先把 DAG 计算出来,以此来避免等待时间过长的情况。
以某些小型以太坊矿场为例。在配置设备以及设置程序的过程中,如果没有预先计算好 DAG,那么每当一个 epoch 过渡的时候,就有可能出现挖矿停滞的状况。在这个期间,就会导致利润的损失。

算法的具体计算过程
以太坊 1.0 中的这个算法要依据程序来生成特定数据。每个 epoch 的 seed 是固定不变的。最后通过 cache 来计算 DAG,light 参数用于保存 cache 数据。DAG 需被存储到文件中,并通过 mmap 映射到内存里。矿机获取当前块头部数据的 hash 值,若此 hash 值满足特定条件,挖矿就完成了;若不满足,就需重新更改 nonce 值,然后再次调用算法。
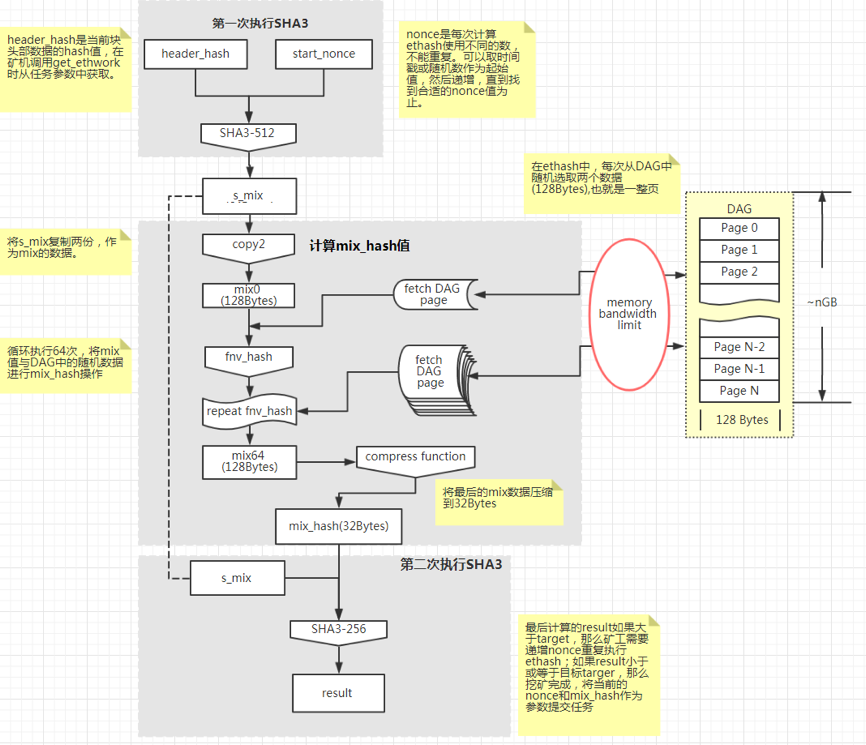
很多矿工在实际操作时,会依据这些规则步骤来定义自身的挖矿流程。倘若对流程的理解不够清晰,亦或是在操作过程中出现错误,那么就有很大可能会致使挖矿失败,或者使得挖矿效率变得低下。
你认为以太坊 1.0 的 PoW 算法在数字货币未来的发展进程中将会处于何种地位?期望大家踊跃点赞,踊跃分享,并且在评论区展开互动。








暂无评论
发表评论