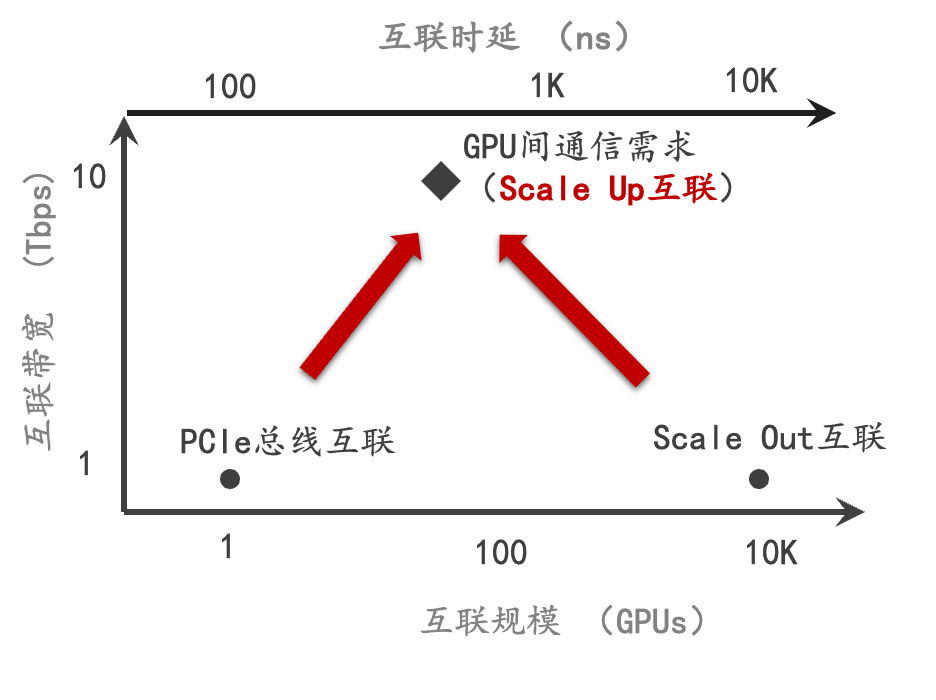
GPU服务器架构正朝着超大规模节点的方向发展,在这一架构转变过程中,涌现出众多新需求与挑战。其中,跨GPU高效数据访问需求显著上升尤为突出。这一重大变革预示着高性能计算的新趋势,但同时也引发了诸多争议,比如如何在追求高效的同时,避免新方案中可能出现的资源闲置问题。
GPU超节点形态的发展
起初,GPU服务器的结构只是单个机器配备一张显卡,但如今已发展成拥有几十甚至数百张显卡的超大规模节点。这一转变并非一朝一夕。以某数据中心为例,它在2018至2020年间,经历了从以单机单卡为主,逐渐增加GPU节点,最终实现大规模超节点架构的演变。这一过程中,投入了巨额成本,包括硬件购置和机房改造等。硬件升级的背后,是应用场景对算力的持续提升需求,例如现代深度学习项目,它们需要大量GPU进行并行计算,以处理海量数据。
这种形态的进步带来了众多益处。例如,在基因测序这一领域,采用大规模超节点GPU架构显著减少了基因数据处理所需的时间。过去,分析一个复杂的基因样本可能需耗时数周,而现在,借助超节点的强大算力,这一过程被大大加速。
ETH - X方案中的分层实施原则
ETH-X计划中,分阶段执行至关重要。该计划着重指出,Scale Up互联协议的实施需根据GPU间互连和访存需求进行分层。以某科研项目的测试为例,在明确了不同层次的需求后,依照ETH-X计划进行连接配置,数据传输效率明显提高。
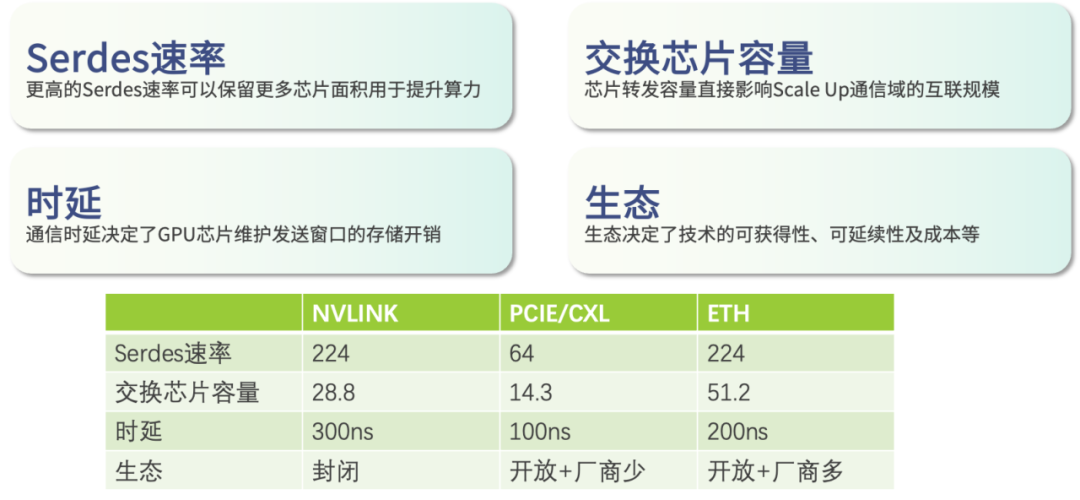
具体能力方面,GPU之间的通信协议依赖于ETH交换芯片的功能。ETH.DMA和ETH.MEM这两种能力集合,向上层提供复制和传输服务。为此,众多科技公司加大了研发力度,2021年的研发资金投入就超过了千万元,专门用于相关芯片技术的开发。
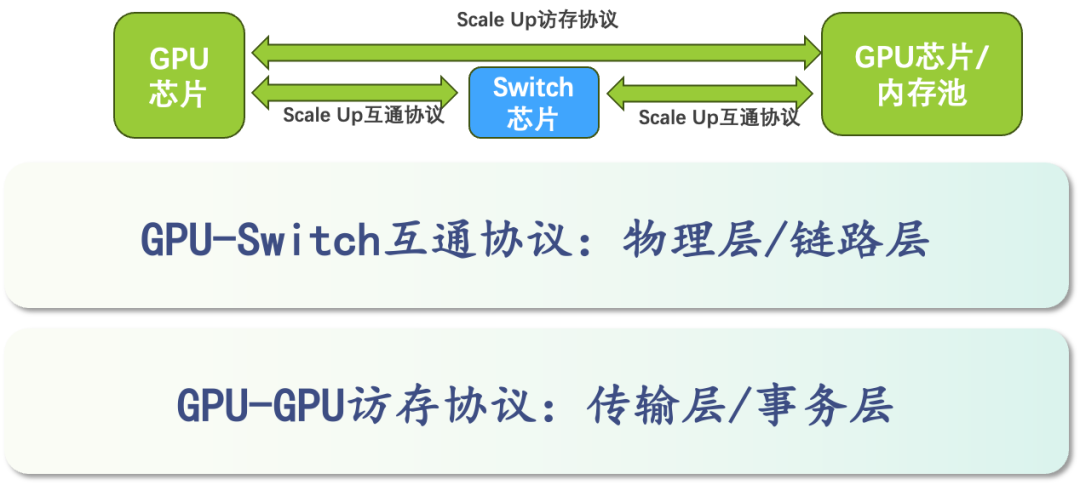
GPU与之间的协议互通
GPU之间,数据传输依赖物理层和链路层的协议。这构成了数据在网络中准确传输、转发及流量控制的基础。在具体网络架构中,例如某公司的分布式计算中心,维持物理链路的稳定是确保整个运算系统顺畅运行的关键。
ETH-X打算运用现有的交换芯片来优化GPU间的连接。以某云端计算服务的数据为例,经过优化,网络在可靠性和流量管理上的表现均有增强,数据传输的精确率也从原先的95%提升至99%。
ETH - X访存协议的实现
ETH-X项目的内存访问协议是连接GPU间内存交流的关键手段。在Scale Up领域,由于GPU设计上的一致性,制造商可以自主完成协议的构建。这种特性便于针对不同的应用场景进行个性化调整。例如,游戏开发企业可以依据不同游戏类型的具体需求,对内存访问进行优化。
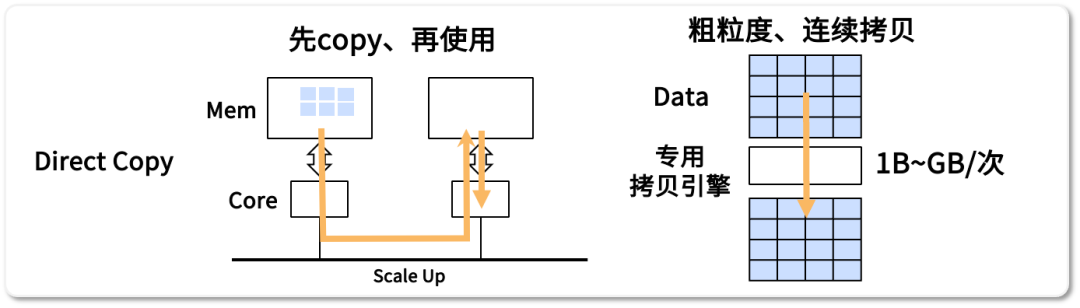
此法通过专用设备有效减轻了CPU的工作压力。比如在图像处理任务中,利用DMA引擎,CPU的负担减少了30%,并且在处理大量结构化数据时效率显著提升。
计算资源潜在空转问题
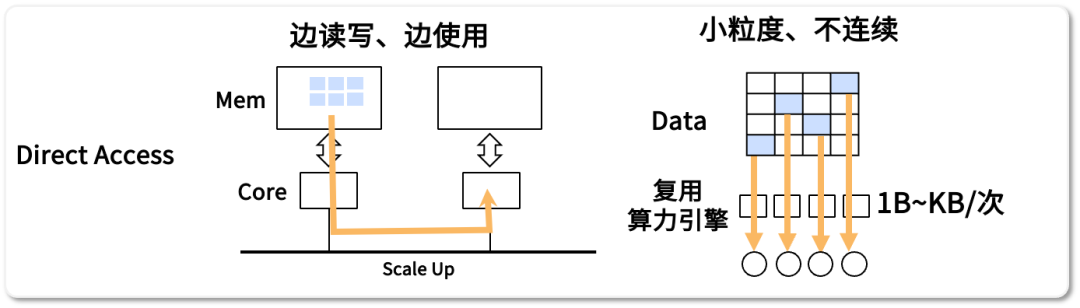
ETH-X方案虽有众多优点,却也存在不足。其算力引擎在访问存储器时,存在同步等待机制。在科学计算测试中,计算流程可能会因数据读写未完成而暂停。这表明计算资源可能会出现闲置,无法充分利用。对于实时金融数据分析等任务,若出现此类闲置,可能引发交易决策的延误。
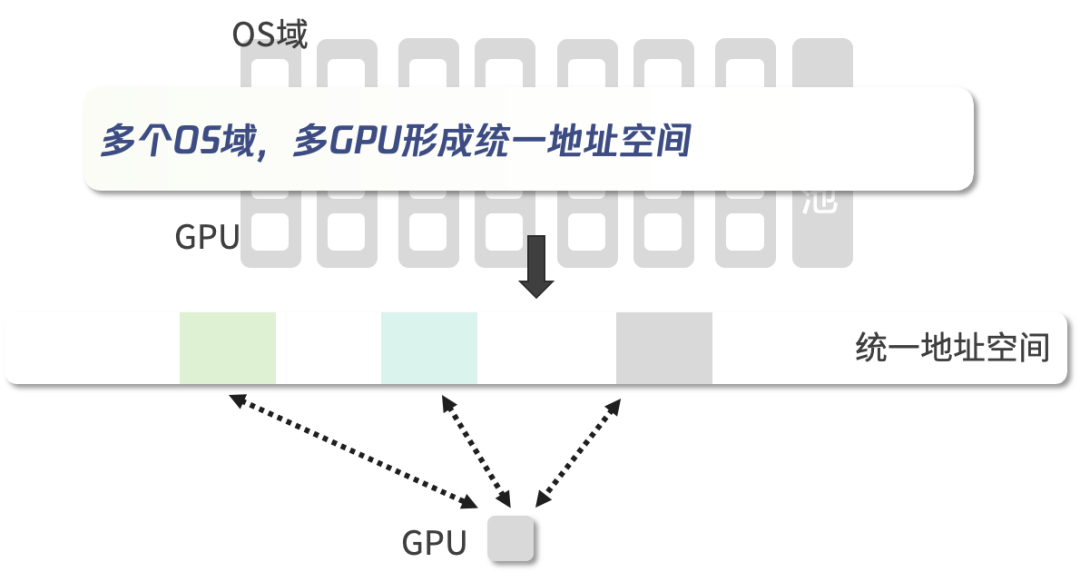
统一内存编址技术
统一内存编址技术使得GPU可以共享虚拟地址空间。这样,多个GPU可以相互直接访问内存。某超算中心应用了这项技术,使得异构计算的编程流程变得更为简便。在硬件层面,页表同步管理对于内存地址的同步起到了关键作用。
这项技术支持对页面进行细致的迁移处理。接入不同存储设备后,能依据访问习惯智能调整数据位置。比如,在降低存储能耗方面,可将不常访问的数据移动至低能耗的存储区域。
Eth.DMA能力集合的作用
在Scale Up互通协议中,Eth.DMA能力扮演着关键角色。它具备流量控制功能,例如PFC、ECN、QoS等,确保网络稳定无故障。以某在线游戏服务器为例,在应用相关技术之前,网络经常出现丢包现象,而采用这些技术后,丢包率显著降低。
提出针对RoCE引擎的优化方案,对于降低成本具有重大意义。这样的方案能减少硬件支出,同时提升计算与数据传输的整体效率。
大家认为,随着科技的持续进步,GPU技术今后还需在哪些方面进行优化?欢迎点赞、转发,并在评论区留下您的看法。









暂无评论
发表评论